主题
模型源
Sage 支持配置多个模型源(Model Provider),让您可以灵活使用不同的 AI 模型服务。
访问模型源
点击左侧导航栏的「个人中心」,在展开的菜单中选择「模型源」,即可进入模型源管理页面。
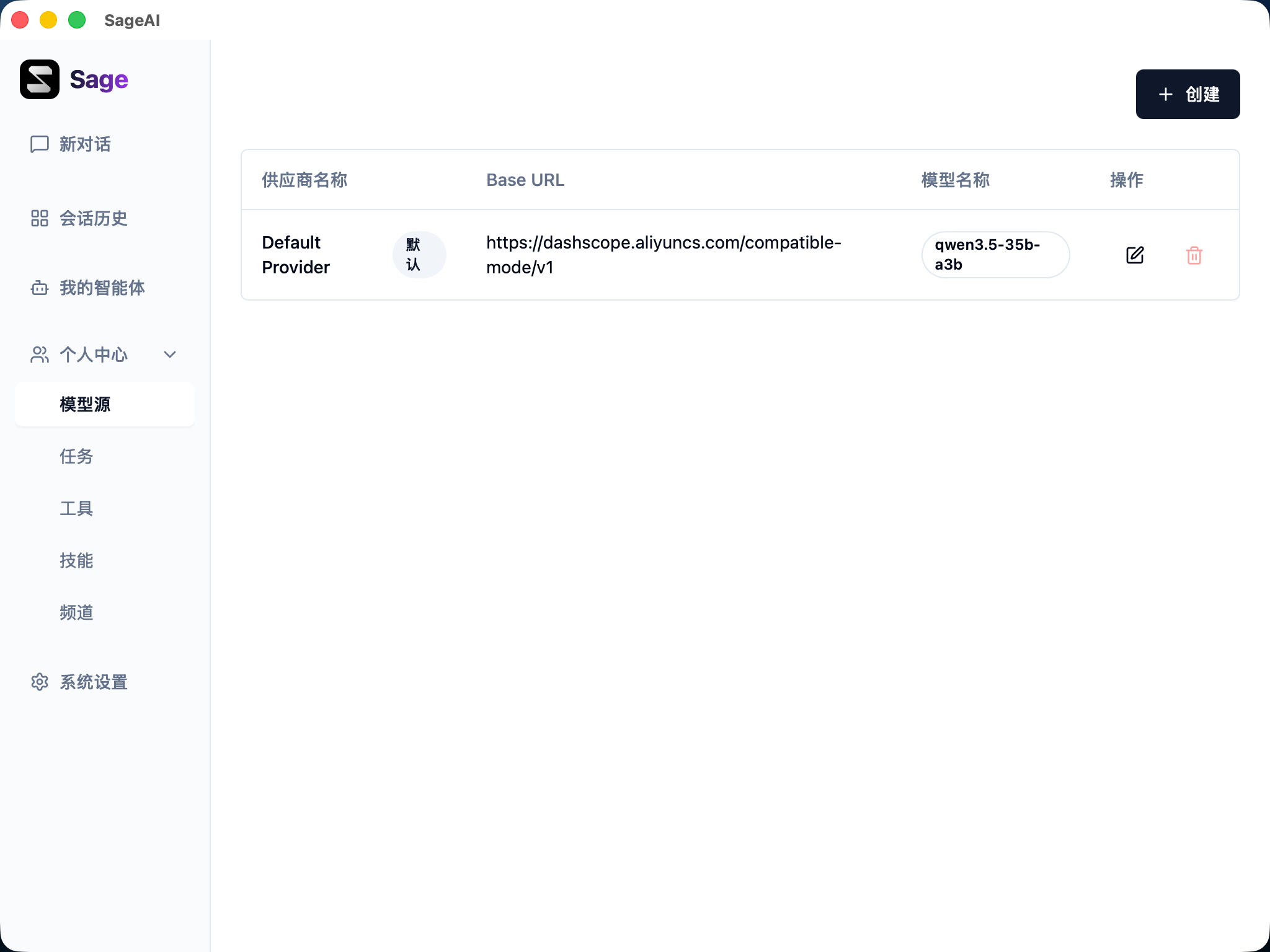
模型源列表
模型源列表展示了所有已配置的模型提供商信息:
- 供应商名称:模型提供商的名称标识
- Base URL:API 服务的基础地址
- 模型名称:当前使用的具体模型
- 操作:编辑或删除模型配置
默认模型源
Sage 会提供一个默认的模型源(Default Provider),首次使用时需要配置 API Key 即可开始使用。
创建/编辑模型源
点击「创建」按钮或列表中的编辑图标,可以创建新的模型源或修改现有配置。
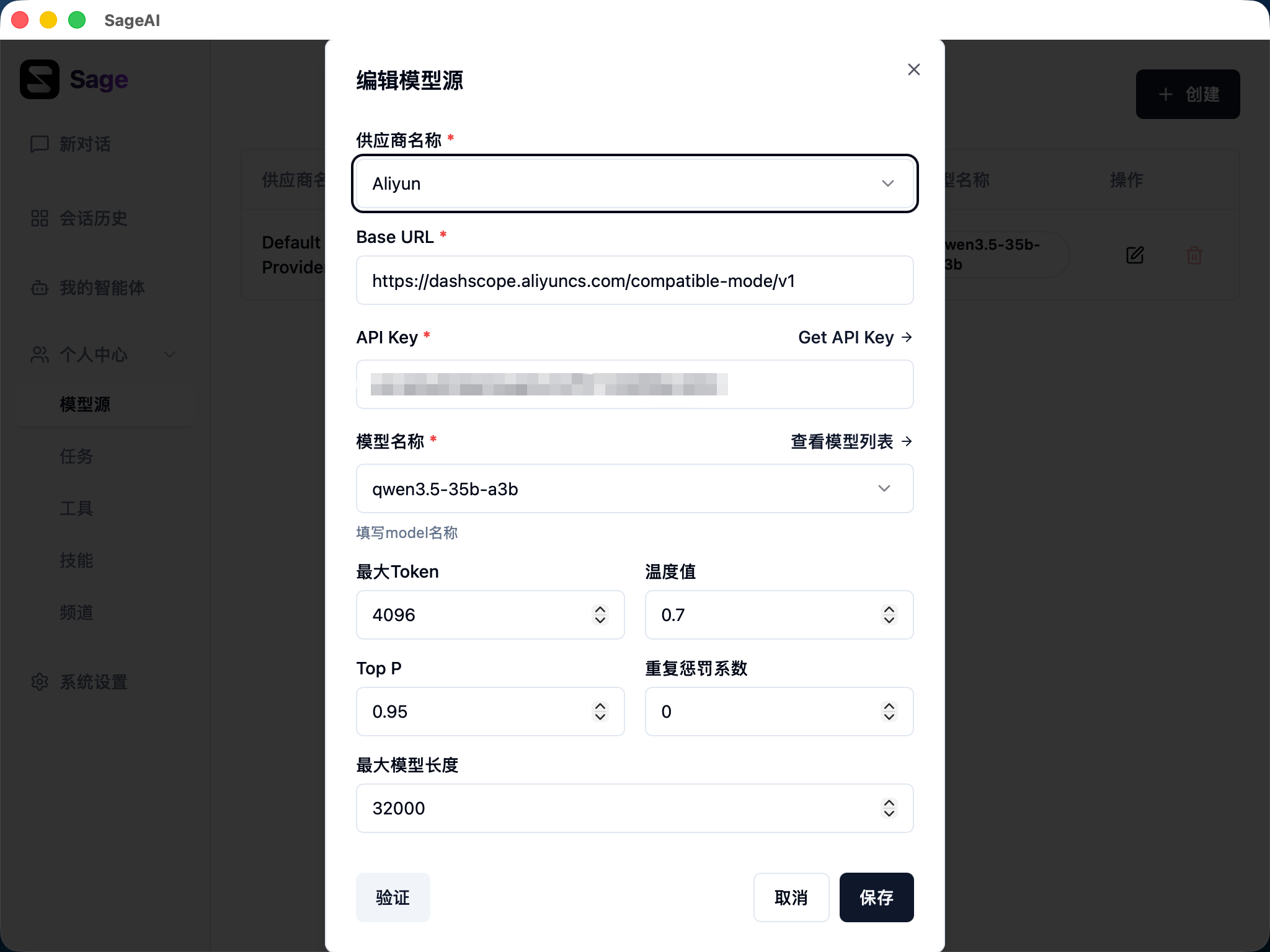
配置项说明
基础信息
| 配置项 | 说明 | 示例 |
|---|---|---|
| 供应商名称 | 为模型源命名,便于识别 | Aliyun、OpenAI、DeepSeek |
| Base URL | 模型 API 的基础地址 | https://dashscope.aliyuncs.com/compatible-mode/v1 |
| API Key | 访问模型服务的密钥 | 从服务商控制台获取 |
| 模型名称 | 具体的模型标识 | qwen3.5-35b-a3b、gpt-4 |
高级参数
| 参数 | 说明 | 默认值 | 建议 |
|---|---|---|---|
| 最大 Token | 单次请求的最大生成 Token 数 | 4096 | 根据任务复杂度调整 |
| 温度值 | 控制输出的随机性,0-2 之间,越低越确定 | 0.7 | 创意任务可调高,精确任务调低 |
| Top P | 核采样参数,控制词汇选择的多样性 | 0.95 | 通常保持默认即可 |
| 重复惩罚系数 | 降低重复内容的概率 | 0 | 出现重复时可适当调高 |
| 最大模型长度 | 模型上下文窗口的最大长度 | 32000 | 影响记忆和成本 |
参数优化建议
关于最大模型长度
适当缩短最大模型长度可以显著降低 Token 消耗,一定程度会影响 Agent 的记忆表现。但 Sage 框架针对上下文管理做了大量优化,包括:
- 智能的上下文压缩和摘要
- 关键信息的优先级保留
- 自动的历史消息管理
因此,即使设置较短的上下文长度,Sage 也能保持良好的对话连贯性。
推荐配置
- 日常对话:4096-8192 Token,温度 0.7
- 代码生成:4096 Token,温度 0.3-0.5
- 创意写作:4096-8192 Token,温度 0.8-1.0
- 长文档处理:根据模型能力设置最大长度
验证配置
填写完配置信息后,点击「验证」按钮可以测试连接是否成功。验证通过后点击「保存」即可生效。
支持的模型服务商
Sage 兼容 OpenAI API 格式的模型服务,包括但不限于:
- 阿里云(通义千问)
- OpenAI(GPT 系列)
- DeepSeek
- 智谱 AI(GLM 系列)
- 月之暗面(Kimi)
- 本地部署(通过兼容接口)
多模型源管理
您可以配置多个模型源,在不同场景下选择最适合的模型:
- 轻量级任务:使用小参数模型,成本低、响应快
- 复杂推理:使用大参数模型,能力强、效果好
- 特定场景:针对代码、数学、创意等任务选择专用模型
在创建 Agent 时,可以选择使用哪个模型源作为后端。